With Nexus Repository Manager v3, Sonatype has turned to the dark side.
I maintain the SciJava Maven repository, a public Maven repository manager (MRM) housing Java components related to the SciJava component collection, including the component stack that powers Fiji, an extensible platform and application for scientific image analysis.
Since around 2010, we have hosted and maintained this resource using Sonatype’s then-excellent Nexus repository manager software, specifically version 2.x thereof, known historically as Sonatype Nexus OSS. Not only did Sonatype provide this wonderful tool as open source, and keep it updated with security fixes, they also published an entire book on best practices with it, while tirelessly hosting and maintaining the vast Maven Central repository at search.maven.org for the open-source software community, all for free. So I have a deep well of gratitude for what Sonatype has done and is doing to elevate the open-source Java community. Unfortunately, this golden age is now coming to an end. But before explaining what I mean by that, some background is needed.
Why run a repository manager
As explained in the Maven documentation, there are two main reasons to deploy a repository manager:
A repository manager is a dedicated server application designed to manage repositories of binary components.
The usage of a repository manager is considered an essential best practice for any significant usage of Maven.
A repository manager serves these essential purposes:
- act as dedicated proxy server for public Maven repositories
- provide repositories as a deployment destination for your Maven project outputs
That second essential purpose—providing a deployment destination for project outputs—is the more obvious one: when I build my JAR files, where do I put them? Python has PyPI, JavaScript has NPM, R has CRAN, Perl has CPAN… and with Java, there is Maven Central. But there is also the ability to self-host your own remote repository and deploy your artifacts there instead.
But why do that? Why not just deploy everything to Maven Central? There are several reasons:
1. To avoid publishing your components publicly. E.g., if your codebase is not open source, you might not want to be publishing its binary outputs out in the open, even if those binaries have been obfuscated (decompiling Java code is very easy). But the SciJava ecosystem is FOSS, so that’s not a reason for us. We do it in public!
2. To avoid the technical complexity and overhead of publishing to Maven Central. Historically, deploying to Central was complicated, done via Sonatype’s OSSRH platform using the now-obsolete nexus-staging-maven-plugin, requiring registration of your groupId (an organization string) under which your components would be deployed, which necessitated manual review and approval by a Sonatype employee. Published artifacts needed (and still need) to meet some minimum metadata quality rules (which is a good thing!), including inclusion of source and javadoc JARs, plus signing of all binaries with a GPG key, which is not trivial to accomplish—if you’ve ever worked with GPG, then you probably know how terrible of a system it is. The newer Central Publishing Portal is in improvement over OSSRH, but the process is still much the same: e.g., releases must still go through a two-stage process where you first deploy (i.e. upload) your binaries to a disposable “staging” repository where they get quality-checked, and then if all is well you can “promote” (i.e. publish) them to the actual public repository.
All in all, publishing to Maven Central is a serious pain to get working, and I say that as a professional software engineer. Many developers of scientific software in my field are not software engineers by training, but rather scientists first and developers second: they are capable of writing Java plugins for Fiji, but it is asking too much for them to go through this convoluted Maven Central deployment process. We first needed to focus on fostering use Maven in our community at all: what benefits dependency management brings, why extending SciJava’s foundational pom-scijava bill of materials is an important thing to do, etc.
Enter the SciJava Maven repository: a deployment target that has been much more seamless than Maven Central for our community. Over a course of many years, we worked with the community to offer deployment access across various GitHub organizations, so that CI can publish artifacts there painlessly: to make a release, the project maintainer just runs release-version.sh, and Maven and GitHub do the rest. In particular: they don’t need to create a Sonatype account, and they don’t need to register their groupId.
There are downsides, of course. To quote a classic blog post from Stephen Connolly:
This is less optimal than the previous solution (publishing to Central) because:
You now add checking two more Maven repositories for every dependency to both your build and anyone consuming your project. This is because Maven does not know what artifacts a repository contains and so must check each repository for the specified dependency, even if you know that dependency will never exist there, Maven doesn’t. And the problem explodes for each new repository included.
In corporate environments, the best practice is to have a Maven Repository Manager coupled within the settings.xml that all employees use. That means that the employees will need to get corporate approval to add those external repositories to their internal Repository Manager. Ultimately this is a good thing, and why the corporates use a MRM, because it gives them control over the code that is being used, and isolates them from failure or disappearance of the upstream repository (their MRM will have permanently cached the artifacts)
In non-corporate environments, I now have to trust that those Maven repositories will not just vanish off the face of the interwebs. While you could argue that there is a similar risk with Central, the reality is that the contents of Central are mirrored to some third parties so if Sonatype were to vanish, the contents of Central are already mirrored to other backup stores managed by other organizations. A six line addition to your settings.xml is all that would be required to get you back up and building until the DNS entries for central were recovered. We cannot say the same for all those small personal/corporate public Maven repositories.
But as he also points out:
Now it is not all bad, because:
- Your jar files’ transitive dependencies are correct
- Your IDE will put the artifacts on its classpath as they are regular dependencies
- Those dependencies are available for others to use
- Someone could always take those artifacts from the repository and publish them to Central (assuming they meet the validation criteria for publishing to central)
Two of the downsides above are worth belaboring further here:
-
“You now add checking two more Maven repositories for every dependency to both your build and anyone consuming your project…And the problem explodes for each new repository included.”
-
“I now have to trust that those Maven repositories will not just vanish.”
Which leads to another big reason to roll out a repository manager:
3. To centralize access to the entire dependency stack, no matter how complicated it gets. If everything we needed to use was deployed to Maven Central, we could just use Central as the central (ha) access point. (I agree with Stephen that Central isn’t going to disappear, and even if it did, we’d figure out as a community how to bring it back in a compatible form.) But there are various components that SciJava-based projects depend upon that are not available on Central: OME, Icy, Jogamp, Jzy3d, netCDF, and Renjin, to name a few. Fortunately, each of these projects deploys artifacts to its own remote repository (and if they don’t, we deploy the binaries ourselves to our own thirdparty area of the SciJava Maven repository). But if we add them all to every SciJava project’s pom.xml, we create two serious problems: first, the multiplicative explosion of remote requests (N repositories times M artifacts being fetched), and second, as soon as any of those repositories goes offline, all of our builds fail due to unfetchable dependencies. This has already happened on several occasions since the SciJava Maven repository was launched!
Happily, those servers disappearing did not break our builds, thanks to the first essential purpose of repository managers: acting as dedicated proxy server for public Maven repositories. The way it works is that you add remote repositories as so-called “proxies” to your remote repository, then collect them into the so-called “public repository group”—in the SciJava Maven repository’s case, the pom.xml block looks like this:
<repositories>
<repository>
<id>scijava.public</id>
<url>https://maven.scijava.org/content/groups/public</url>
</repository>
</repositories>
By adding one single repository to the Maven build, SciJava projects gain access to all of the artifacts available from all of the remote repositories of all of the above projects: our SciJava repository itself reaches out on demand to locate requested artifacts, and once found, it permanently caches those artifacts, so that we don’t have to bother the original source repository for those artifacts again. Even if a source repository goes offline, as long as the artifacts have been cached in this way, builds still succeed because the SciJava Maven repository can continue to provide them directly. Developers limit their “trust surface” to only maven.scijava.org, and I remain fanatically dedicated to keeping it running for the long haul.
This has worked brilliantly for the past 15 years. But then Sonatype decided to do something nasty: they added a strict limit to the number of binary components that can be stored in Sonatype Nexus without paying for an expensive commercial license. And thus begins our tale of woe.
Being a good citizen of the Maven ecosystem
With the SciJava Maven repository, I have always striven to follow best practices. Deploy a public Maven repository. Proxy Maven Central, and other repositories housing components we use, to help ease the burden of traffic. Such was the conventional wisdom of the Maven community. And Sonatype provided Nexus OSS to achieve these goals. Even Brian Fox, Sonatype’s CEO, explicitly encouraged this back in 2009:
In my experience, it is best to let your CI system deploy your snapshots. This is the most reliable way to ensure that the contents of your repository are kept in sync with your source control system. To do this practically, you need to couple CI with a repository manager like Sonatype Nexus Repository that can automatically purge snapshots.
Aside: snapshots versus releases
Having a place to deploy SNAPSHOT builds easily was historically another reason to use a repository manager. While Sonatype’s new Central Portal infrastructure supports snapshots in a straightforward way, and so did its previous OSSRH mechanism, it has much of the same setup complexity that using Central for releases does.
Over the years, the message has remained consistent:
For nearly two decades it has been a well-understood best practice to leverage a repository manager as a caching proxy. Not only does this reduce the load on the central repositories, but it improves your own build performance and reliability by caching the components needed by your builds instead of fetching them from the internet 10,000 times a day.
Fox reports in that same blog post that “83% of the total bandwidth of Maven Central is being consumed by just 1% of the IP addresses. Further, many of those IPs originate from some of the world’s largest companies.”
In another blog post, Fox elaborates:
We’re now observing entire organizations downloading the same components over half a million times per month, not for a few isolated libraries, but for thousands of artifacts. This is not a one-off anomaly; it’s systemic overconsumption that replicates across vast internal build systems, CI/CD pipelines, and hybrid cloud deployments.
Even more damningly, as he writes on this Gradle issue:
Lately I’ve noticed a recurring pattern that within these enterprises, they all have a repository manager already and the vast majority of their trafffic is coming from Gradle builds that are bypassing the repo.
In other words: a big part of the load on Maven Central is due to large organizations with thoughtless or misconfigured development processes that externalize their costs in ways they don’t even notice, and are incredibly wasteful and unnecessary.
We have increasingly observed such patterns within our community as well: single clients rapidly and systematically trying to download all of Maven Central via from maven.scijava.org, which brings down the MRM, resulting in failing CI builds for the legitimate users in our community. Fortunately, for our little corner of the Internet, I was able to address this issue with strategies like permanently banning (via iptables) IP addresses accessing large numbers (10K+) of components in one day, when <100 of them (i.e. <1%) were for SciJava-related components. But for a massive system like Maven Central, the solution is much more complex and difficult, with many more bad actors in the mix. So I sympathize with Sonatype’s plight in maintaining this crucial resource for the worldwide software development community.
Coercing good citizenship
In one of Fox’s blog posts, he calls out our shared responsibility as a community for sustainability, embedded in an explanation of how Sonatype is fighting back against large-scale abuse:
Our goal is not to punish heavy users, but to ensure that every organization contributes to the health and sustainability of the ecosystem we all rely on.
I agree passionately! But Sonatype’s business choices have become misaligned with this messaging:
They deprecated and retired Nexus OSS v2, introducing a new Nexus v3 in two editions: Nexus Community and Nexus Pro. Actually, there are three editions, Nexus Core being the ostensible base for the other two, but the overview of editions on their website makes no mention of it, Sonatype offers no support for it, and I suspect it is left intentionally difficult to get working to make the other editions as attractive as possible by comparison. Its existence does however enable Sonatype to brand Nexus Community and Pro as “OSS” even though they contain closed-source components and crippleware restrictions!
The Sonatype Nexus v2 software, including Sonatype Nexus OSS edition, hit end-of-life on June 30, 2025 (note: the Nexus Repository Manager 2 is Now End-of-Life article erroneously lists the EOL date as June 30, 2024). Most of the Nexus-v2-related resources were taken offline, including the Nexus book. The Sonatype Nexus website upgrade documentation now declares:
Action Required: All versions on Nexus Repository Manager 2 are no longer supported. Upgrade to a supported version.
And the Sonatype Nexus v2 user interface itself also declares itself as unsupported, even in anonymous view, announcing to the world the lack of future security patches. The pressure to update to Nexus v3 is unrelenting.
Aside: Nexus EOL info on endoflife.date
This page from endoflife.date is actually better than Sonatype’s website in explaining the evolution of Nexus from v2 into v3 as well as the database. But it’s still incomplete: no mention of Orient specifically, no mention of the introduction of component limits, nor which version (3.76? 3.77?) started to enforce them.
My upgrade experience
Before I upgraded the SciJava Maven repository to Nexus v3, I had no idea about the crippleware restrictions. I actually had a completely different concern: I read that Nexus v3 is a total rewrite of v2 that switches to a mandatory blob store approach even for file-system-based repositories like ours. I had developed some tooling capable of running on the repository server’s file system to reason about Maven components in a much more efficient way than you can do using the Nexus REST API, which is orders of magnitude slower by comparison, and I was concerned that switching to Nexus v3 would destabilize the service.
The flat-file organization of Nexus v2 was one of the many great things about it. Here’s Brian Fox answering a question about Nexus versus Artifactory on Stack Overflow in 2008:
Artifactory stores the artifacts in a database, which means that if something goes wrong, all your artifacts are gone. Nexus uses a flat file for your precious artifacts so you don’t have to worry about them all getting lost.
I was sad to see that go, so I put off the upgrade as long as I could. But when the actual end-of-life date drew nigh, I knew I could wait no longer, and dove into the effort.
As one does, I started by reading the official documentation: Sonatype Nexus Repository led to Upgrade from Nexus Repository 2 which explained the built-in upgrade wizard, which sounded ideal for us. I was particularly heartened to see support for a hard linking mode:
Hard Linking does not require the file system to copy components as it updates the file pointer to the content stored on the disk. While limited to in-place upgrades, this method greatly shortens the time and storage required to run the upgrade.
Awesome! I proceeded to the Upgrade Wizard page to verify that we met the prerequisites.
Aside: for Sonatype: suggested improvements to the documentation
In case anyone from Sonatype ever reads this post, I wanted to highlight some specific problems I stumbled over while upgrading our Nexus installation, and suggestions for improvement.
Executive summary:
- Quick Wins:
- Update feature matrix with actual CE limits
- Add component/request limits to all upgrade documentation
- Create database compatibility matrix
- Move H2 limitations to licensing discussion
- Fix inconsistent version recommendations
- Longer-term Improvements:
- Add clear mentions of Core/OSS documentation
- Fix the Core/OSS build
- Provide component counting transparency
- Create academic/OSS-specific guidance
- Practice more honest naming for limitation-based tiers
Nexus Repository Feature Matrix:
- Community Features table: “Unlimited Nexus Repository Deployments” has green checkbox for Community Edition (CE). But this is no longer true.
- The word “limit” does not otherwise appear on this page at all. The limitation numbers should appear in the table.
- The Nexus Core/OSS (which must be built from source) does not appear as a column. It should.
Upgrade from Nexus Repository 2
- No mention of Community edition’s component or daily usage limits.
Community Edition (CE): both instances must be on corresponding versions of Nexus Repository 2 and 3. Nexus Repository 3 CE deployments need to migrate to 3.76.0 deployed with Java 17 using an H2 database before upgrading to later versions.
👆 This is crucial information! Great that it is stated here. Wizard pages should also say this explicitly. A table indicating which Nexus versions support OrientDB, H2, and PostgreSQL would be useful to understand it better at a glance. Something like:
| Version | OrientDB | H2 | PostgreSQL |
|---|---|---|---|
| 2.x | yes | no | no |
| 3.0 - 3.76 | yes | yes | yes |
| 3.77+ | no | yes | yes |
(Not sure the data above is correct, but just for illustration of what I think would be helpful.)
Sonatype Nexus Repository System Requirements
I read this page before upgrading. I saw in the “Database Requirements” section the following note:
New installations are configured to use an H2 database by default. Nexus Repository running with the embedded H2 database supports up to 200,000 requests per day or 100,000 components.
I was not sure whether that would be a problem for us (I didn’t know what counts as a “component” nor how many such our Nexus 2 installation currently had). But I saw the recommendation to use a PostgreSQL database in the following paragraph, thought that would be doable for us, and tentatively planned to migrate from H2 to PostgreSQL after upgrading to Nexus 3, as needed based on behavior and performance.
The implication is that this is a performance limitation of H2 somehow, not PostgreSQL, nor Nexus itself. But the reality is that it’s the Nexus Community software that has been limited in this way; using PostgreSQL does not mitigate it whatsoever. Therefore, this notice does not belong in this section. This support limitation belongs in a licensing requirements discussion (because Pro is needed), not one about system requirements, which are intended to help DevOps teams allocate hardware resources.
OrientDB is not supported in version of Nexus Repository past the 3.70.x branch. Your Nexus Repository instance must be on the latest 3.70.x version to migration from OrientDB.
Here it says to use 3.70, whereas on the Upgrade from Nexus Repository 2 page it says to target 3.76, and on this forum topic a responder suggests 3.77. (I found that forum topic because my initial upgrade attempt from 2.15-03 to 3.82.x failed due to no Upgrade capability being available.)
- No mention of Community edition’s component or daily usage limits.
Community Edition (CE): upgrade to the 3.76.0 release with H2. After the upgrade, migrate to the latest release with PostgreSQL.
This statement led me to believe I would want/need to migrate the database to PostgreSQL after completing the v3 upgrade itself, which led me to read the Migrating to a New Database guide, which I found confusing. It would be good for the database migration page to state up front: A) which versions of Nexus support OrientDB, H2, and PostgreSQL; and B) which databases are used “out of the box” by Nexus v2 and Nexus v3. In the section “OrientDB Migration on Nexus Repository 3.70.x branch”: the “3.70.x” terminology indicates that 3.76.x and 3.77.x do not support OrientDB, but my understanding is that actually they do. And 3.76.0 is the recommended upgrade target from Nexus v2 according to the “Upgrade Wizard” page.
It turns out that migrating to PostgreSQL was not needed for our system; H2 is still available and works well for the scale of our repository installation. I would soften language around the Community Edition upgrade statements to mention that doing so is optional; something like: “If you plan to migrate your database to PostgreSQL for performance reasons (recommended for larger-scale installations), do so as a separate step after performing to v3 upgrade itself.”
I missed the note on the “Upgrade Wizard” page about upgrading to 3.76.0 first (mentioned in step 5), and initially tried migrating to the then-latest 3.x version, which was 3.82.0. It would be good to add a hint that if the Upgrade Capability is not available in the Nexus v3 interface, to double-check that the Nexus v3 version being targeted is indeed 3.76.0 and not any later version.
Changes during the Upgrade Process:
- No mention of Community edition’s component or daily usage limits.
Introducing Nexus Repository Community Edition: Enhanced Features for Growing Teams:
It’s important to note that our open source EPL core (OSS) is not and has not changed. You can still benefit from the exact same core functionality and formats (apt, Maven, raw) that have been available for more than a decade. Most free users will likely transition to the more feature-rich Community Edition, but those who prefer to use the OSS tier are welcome to do so.
The Nexus Core repository build has been broken for at least several months. The tests fail, and the final built fat JAR artifact fails to launch successfully. The simplest support requests go unanswered.
Furthermore, the “Community Edition” naming is disingenuous. If you surveyed 100 developers and asked them what they would expect the differences to be between the Community and Pro editions of some arbitrary software tool, I bet they would say two things: 1) Community edition is free (as in $) but unsupported, and 2) Pro edition has more features and/or has commercial support. They would be unlikely to guess that the Community edition is crippleware, with hardcoded limitations like component or daily usage limits. Those kinds of limits are traditionally in the realm of a demo or free trial piece of software. It would have been more honest to name this “new tier” something different—any of “Nexus Individual” or “Nexus Plus” or “Nexus Small Team” would be less misleading than “Nexus Community Edition”.
It was also disingenuous to strip all mentions of Core/OSS from the Sonatype website.
General Comments:
- Everything feels like a funnel toward Pro now, rather than an honest attempt to help each person or org understand the most recommended path forward for them.
- Articles like Maven Central and the Tragedy of the Commons explain why it’s more important than ever to use a proxying MRM, but unfortunately, Nexus 3’s component limit now disincentivizes people from doing that, because proxied components are counted in the Total Components.
At this point, I want to reiterate that Nexus v3 is crippleware: as of this writing, it has a limit of 40,000 components in the repository, with no more than 100,000 total requests per day to access them. This is a critical consideration when upgrading from Nexus v2! But none of the pages in the above sequence mention this limit in any way.
Even setting aside the crippleware issue, the upgrade instructions are convoluted, complicated by the rollout of many versions of Nexus v3 over time, some of which made stepwise-incompatible changes away from the original v3.0.0 release. One must first upgrade to v3.76.0, the last version to support the OrientDB backend used by Nexus v2, then migrate to the newer H2 database, then migrate again to the latest version of Nexus v3. Personally, I would have dubbed the first non-OrientDB-compatible Nexus as v4.0.0, to more clearly communicate that there is a necessary upgrade step at that juncture—but that’s a forgivable mistake. The much bigger issue is the failure across nearly all of the Nexus documentation to disclose—I suspect intentionally—that Nexus v3 Community has hard limits baked into it that entrap organizations into a suddenly-broken-in-production situation where the simplest way out is to pay Sonatype thousands of dollars annually for a Nexus Pro license.
Post-upgrade challenges
No more proxying Maven Central
After upgrading and logging into the upgraded Nexus, the crippleware limits were immediately obvious. Here is how it looks as of this writing:
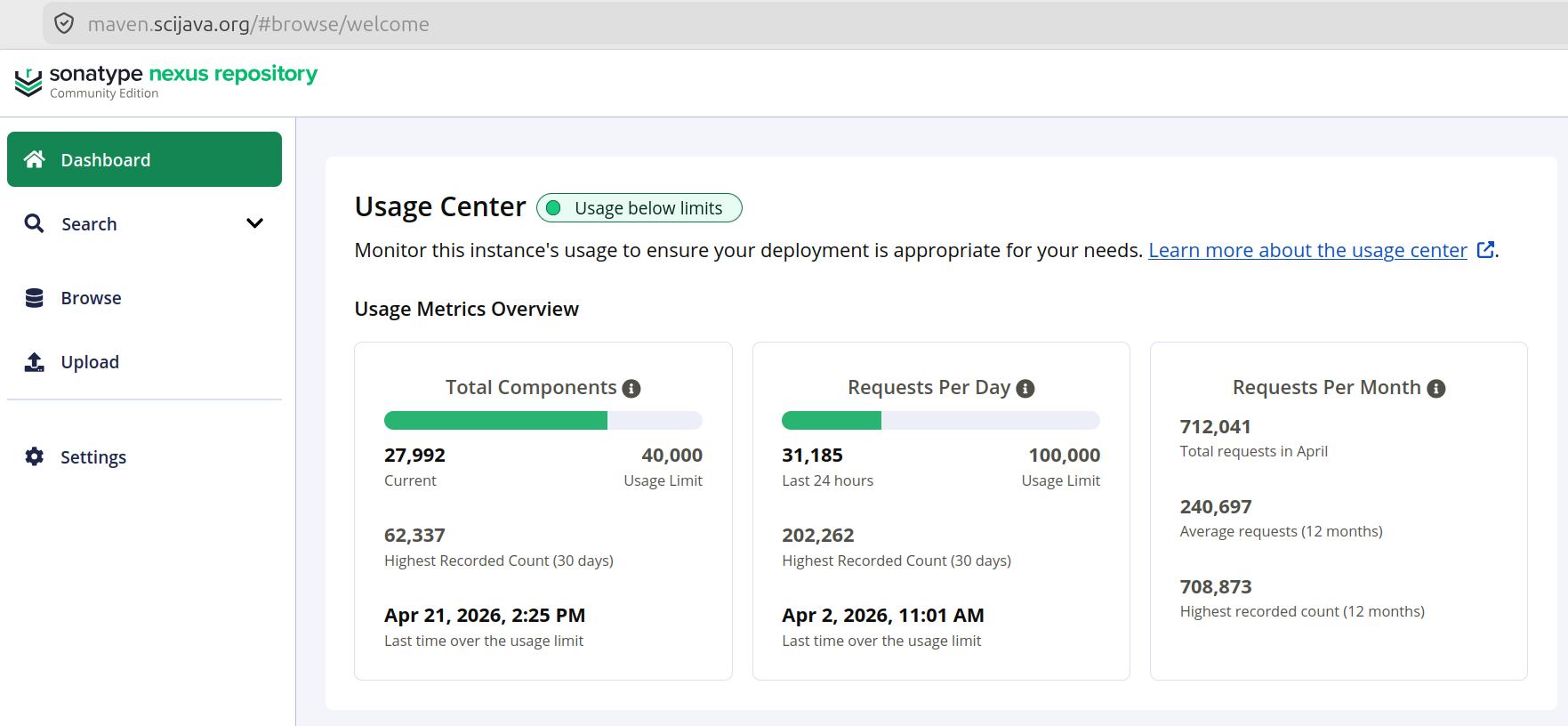
But it took some major changes to get to that point where the bars are all green and happy.
When I performed the upgrade last year, the component limit was 100,000, not 40,000. But thanks to many years of builds across the community, there were many thousands of components from Central cached, which inflated the component count to more than twice the limit.
To address this, I had no choice but to purge the Maven Central cache. Unfortunately, in the coming days, the cache simply filled up again, and it was apparent that continuing to proxy Maven Central was no longer going to be possible for us. Fortunately, every Maven build already includes Central as the last fallback when other configured repositories fail to deliver a requested artifact. So all our projects currently including maven.scijava.org in their <repositories> list would still build just fine without the Maven Central proxy in place on the server side—they would just build more slowly as artifacts from Central are requested twice instead of once (first from maven.scijava.org, which returns 404 Not Found, and then successfully from repo1.maven.org/maven2 successfully).
This is a truly disheartening compromise: Sonatype’s business direction here has resulted in our subcommunity actually becoming worse citizens of the Maven ecosystem. Rather than doing our part to take the load off of Central like we did before, we now externalize those costs. I actually had a video call with the Sonatype people about this issue late last year, and when I brought up this concern, they just scoffed; at the scale Maven Central operates, they said, the increased bandwidth draw from our community is inconsequential. That may be true, but what happened to the ethos of efficiency and cooperation?
No more active proxying AT ALL?
Ceasing to proxy Maven Central has created more problems than were apparent at first. In the past couple of weeks, I became aware that the SciJava Maven repository has been hammering other remote repositories including Unidata’s. I suspect the reason is that because we no longer proxy Maven Central, every artifact of every build in our community goes through maven.scijava.org which reaches out to all its proxies for every artifact, even though they 404ed before, because you never know, they might have been deployed there since last time! There is actually a “Not found cache TTL” set to 1440 minutes (24 hours) for all the repositories we proxy, but as described above, when aggressive clients systematically request every Central artifact from maven.scijava.org, it will then do so from every proxied repository, at least once a day. No good!
A better solution is so-called “Routing Rules”: Nexus v3 supports assigning regexes for path matching to each repository proxy, so that the SciJava Nexus does not reach out to the downstream repository unless the request matches a groupId (e.g.) we know we want from it. I am in the process of configuring such rules now, which I hope will allow us to continue proxying the key repositories we need in our community without abuse targeting our repository spilling over to those downstream.
Hitting the daily request limit
Such abusive behavior (intentional or not) also recently kicked us over the other new limit that Nexus v3 imposes: the daily limit of 200,000 (at the time—since reduced to 100,000) requests.
The Apache access logs revealed an unexpected primary culprit: Facebook’s meta-externalagent web crawler, accounting for approximately 63,000 of the ~197,000 successful (HTTP 200) responses recorded that day—roughly 32% of the entire daily Nexus request budget consumed by a social media link-preview bot. Perhaps someone had shared a maven.scijava.org URL on Facebook or Instagram at some point, and the crawler had obediently followed every link it found and indexed the entire artifact tree? A further ~11,000 successful responses came from other non-Maven bots such as YisouSpider; the remaining ~123,000 more requests came from Maven, Gradle, and Coursier clients distributed across many IP addresses—ordinary background traffic of the scientific Java community going about their work? But still an order of magnitude higher than a normal day.
One mildly reassuring finding: Nexus’s daily request limit appears to count only HTTP 200 responses, not 404s or other errors. This matters because maven.scijava.org also received approximately 351,000 HTTP 404 responses that same day, generated by CI pipelines querying it for Maven Central artifacts that are not cached there anymore. These pipelines have maven.scijava.org somewhere in their POM’s <repository> list, and Maven dutifully queries every listed repository for every artifact it needs. While not counting against the daily limit, it still imposes real load on the Apache proxy and Nexus itself, consuming memory and CPU for requests that will never succeed.
Fortunately, dealing with the daily request limit is much more tractable than the component count one: we configured Apache to use mod_cache_disk, caching all release artifacts with a 24-hour TTL. Release artifacts are immutable by Maven convention, so this is safe: a repeat download of the same JAR or POM now serves from Apache’s cache and never reaches Nexus, saving it from being counted against the daily limit. We also blocked known web crawler user agents (meta-externalagent, YisouSpider) before those requests reach Nexus, and added a robots.txt disallowing /content/, /repository/, and /service/ to prevent re-crawling.
While these changes substantially reduce the daily request count Nexus sees, they also illustrate how much operational complexity the new hard daily limit has created for a public repository that serves a broad and diverse community.
Tightening the screws
With the release of Nexus v3.87.0 late last year, the already problematic component limit was cut by another order of magnitude, from 100,000 to 40,000, and the daily request limit also reduced from 200,000 to 100,000. The Nexus user community is not pleased.
Not knowing this, I upgraded the SciJava Nexus to v3.91.0 yesterday as part of due diligence versus the impending AI security apocalypse, and was truly shocked to see this component limit reduction. We were once again over the limit: ~62,000 components as of a couple of days ago. To address the issue expediently, I ran a component scan across all of the proxied repositories to identify the ones housing the largest number of components—turns out it was our proxy of maven.google.com. My solution: delete the proxy repository, and cross my fingers that none of our builds actually depend on it—after looking at its contents, I honestly cannot remember why I added it in the first place. If builds break because of it, we can readd the proxy, let it reestablish the needed artifacts in the cache, and then lock it down to limit any further growth. The addition of Routing Rules as mentioned above will probably also help a lot.
What’s next?
Let’s conclude this obnoxiously long post as per usual: by talking about the future!
What are we going to do now? How can we avoid renewed problems going forward?
Purchase Nexus Pro? Even with an academic discount, it’s >$4K/year—not within our budget. And even if we had the money, we have better things to spend it on, like hackathons.
Downgrade to Nexus Core/OSS? Clone the mirrored repository from GitHub, build from source, get it running? I already tried, twice, but the tests fail, and when you skip them, the final built artifact (a fat JAR) crashes on startup. It has been like that for many months, and I do not expect that Sonatype will ever fix it.
Hack around the limitations? Since Nexus v3 Community is largely built on the open-source Nexus v3 Core, it should be possible to disable the crippleware limits via reverse engineering. Java is easy to decompile; I already discovered that the crippleware subsystem is powered by a ServiceLoader-discovered interface implementation. But a quick try at slotting in a more permissive implementation does not immediately work—I’m guessing there is some obfuscation in place. While it can probably be defeated, I am not eager to enter an arms race with a company that I have until recently admired so much.
Switch to a different repository manager? I feel this is the most promising way forward. Two projects I’m interested in testing are Reposilite, which I noticed is running in production on Unidata’s Maven repository, and Artifact Keeper, a promising-looking recent effort that has a dedicated Nexus migration guide. But researching and testing these things takes time, and I have no idea when I’ll be able to make room for it. Probably when Sonatype cuts the Nexus v3 component limit in half again. -_-
Finally, we will phase out use of the SciJava Maven repository for deployment of new releases. For all the groupIds I develop and/or maintain (org.scijava, net.imglib2, net.imagej, io.scif, sc.fiji, and org.apposed), deploys to Central are already configured—I just need to cut new releases of every component from the bottom up, until everything is on Central. And once we’re dogfooding our releases more completely, we can work to migrate the many other groupIds in our community one by one, until no one is deploying to the SciJava Maven repository anymore, at which point it will become a read-only archive used primarily for old builds, and we can leave the complexity of a full-blown MRM behind us.